Vind verbanden en patronen met data mining analyses
Data mining laat je interessante verbanden en patronen vinden in datasets waar je als mens niet zo snel op zou komen. Zo werd op een mooie dag een vader verrast met allerlei aanbiedingen van producten die vrouwen vaak tijdens zwangerschap kopen, de supermarkt wist eerder dan hijzelf dat zijn dochter in verwachting was. Data mining laat je met behulp van machine learning, statistiek en databasetechnieken zeer verfijnde kennis opdoen over je klanten, processen en producten. Helemaal onomstreden is data mining echter niet. Er zit ook een ethische kant aan – de supermarkt bracht dochterlief behoorlijk in verlegenheid – en zonder elementaire kennis van de statistiek kun je al snel verkeerde conclusies trekken. In dit artikel beschrijven we wat data mining is, welke 6 stappen je zet in het data mining proces en geven we maar liefst negen voorbeelden van succesvolle toepassingen. We gaan ook in op data mining software en laten je kennismaken met een ervaren data mining consultant. Tot slot geven we nog enkele praktische tips waarmee je resultaat kunt boeken.
Wat is data mining?
 Data mining, artificial intelligence en big data worden vaak in één adem genoemd. Hetzelfde geldt voor data mining, deep learning, data science en predictive analytics. Hoewel al deze begrippen veel met elkaar te maken hebben, zijn er wezenlijke verschillen. Om begripsverwarring te voorkomen werken we daarom met een eenduidige data mining definitie.
Data mining, artificial intelligence en big data worden vaak in één adem genoemd. Hetzelfde geldt voor data mining, deep learning, data science en predictive analytics. Hoewel al deze begrippen veel met elkaar te maken hebben, zijn er wezenlijke verschillen. Om begripsverwarring te voorkomen werken we daarom met een eenduidige data mining definitie.
Data mining is het vinden van verbanden, patronen en correlaties in gestructureerde data met behulp van machine learning, statistiek en databasetechnieken.
Het ultieme doel van datamining is het opdoen van nieuwe inzichten die “verborgen” zitten in data en het vergaren van nieuwe kennis. Die gebruik je vervolgens weer om betere beslissingen te nemen, processen te optimaliseren en zelfs te innoveren. Data mining is een vakgebied dat zich vooral richt op geautomatiseerde analyse van gestructureerde data waardoor je nieuwe, verfijnde kennis op kan doen. Maar het is zeker geen vakgebied dat in isolatie kan functioneren. Je hebt minimaal de volgende bouwstenen nodig om succes te bereiken:
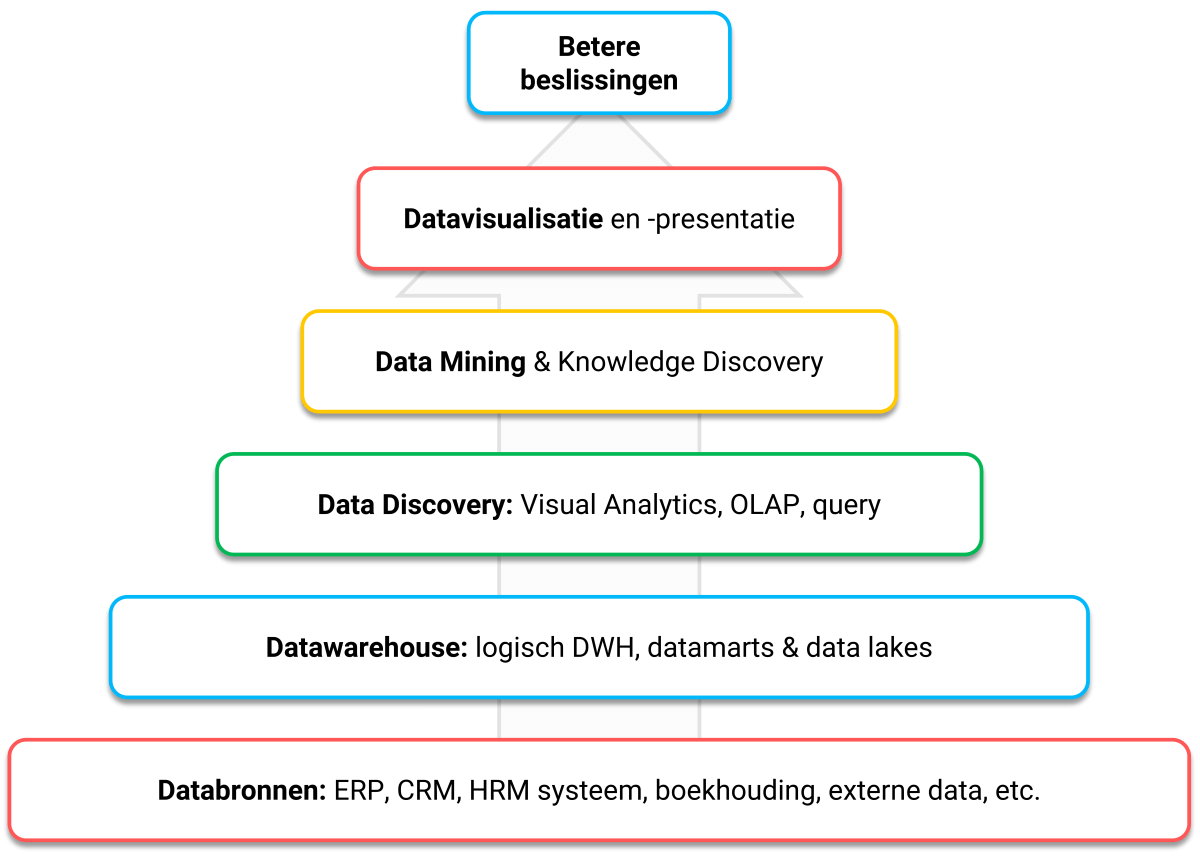
Figuur 1: Een diagram dat illustreert welke bouwstenen nodig zijn voor data mining en wat het doel is.
- Databronnen: selecteer en onttrek gegevens uit bronnen van hoge kwaliteit
- Datawarehouse: combineer gegevens uit verschillende bronnen en zet die bij elkaar
- Data Discovery: keer de benodigde data binnenstebuiten, ken je gegevens door en door
- Data mining software: laat statistiek en machine learning los op de verzamelde gegevens
- Datavisualisatie: visualiseer de patronen en verbanden zodat iedereen die kan begrijpen
- Betere beslissingen: maak beslissingen datagedreven en verbeter ze structureel
Hoewel de pijl in de figuur van beneden naar boven loopt, raden we je aan om te beginnen bij de beslissingen die je wilt verbeteren in het primaire proces en niet bij de databronnen. Begin dus met een helder doel. Je brengt daarmee de juiste focus aan in jouw data mining project.
Waar liggen de wortels van data mining?
 De wortels van data mining of “datamining” (volgens de spelling van het Groene Boekje) gaan helemaal terug tot in de 18e eeuw toen de Bayesiaanse kansberekening, de waarschijnlijkheidstheorie en regressieanalyse als onderdelen van de wiskunde hun opwachting maakten.
De wortels van data mining of “datamining” (volgens de spelling van het Groene Boekje) gaan helemaal terug tot in de 18e eeuw toen de Bayesiaanse kansberekening, de waarschijnlijkheidstheorie en regressieanalyse als onderdelen van de wiskunde hun opwachting maakten.
De term data mining als concept dook echter pas in 1990 op binnen databasekringen. Werd eerst nog formeel gesproken van Knowledge Discovery in Databases, afgekort als KDD, later raakte de term datamining steeds meer in zwang.
Gelet op deze historie en het onderzoekende karakter van datamining is het niet vreemd dat data discovery een algemeen geaccepteerd synoniem is voor data mining. Data science is de verzamelnaam voor datawetenschappen in de meest ruime zin. Functionarissen in het bedrijfsleven of wetenschappers aan universiteiten die zich met data mining en data science bezighouden worden logischerwijs data scientists genoemd.
Wat is het verschil met process mining?
Process mining en data mining worden in de praktijk heel vaak door elkaar gehaald, of erger nog, op één hoop gegooid. Desondanks is het aantal verschillen tussen beide concepten groter dan het aantal overeenkomsten. Laten we met de belangrijkste overeenkomsten beginnen. Zowel data mining als process mining vallen onder de brede paraplu van Business Intelligence & Analytics. Beide maken bovendien in toenemende mate gebruik van machine learning algoritmes om verborgen patronen, (causale) verbanden en onregelmatigheden te ontdekken.
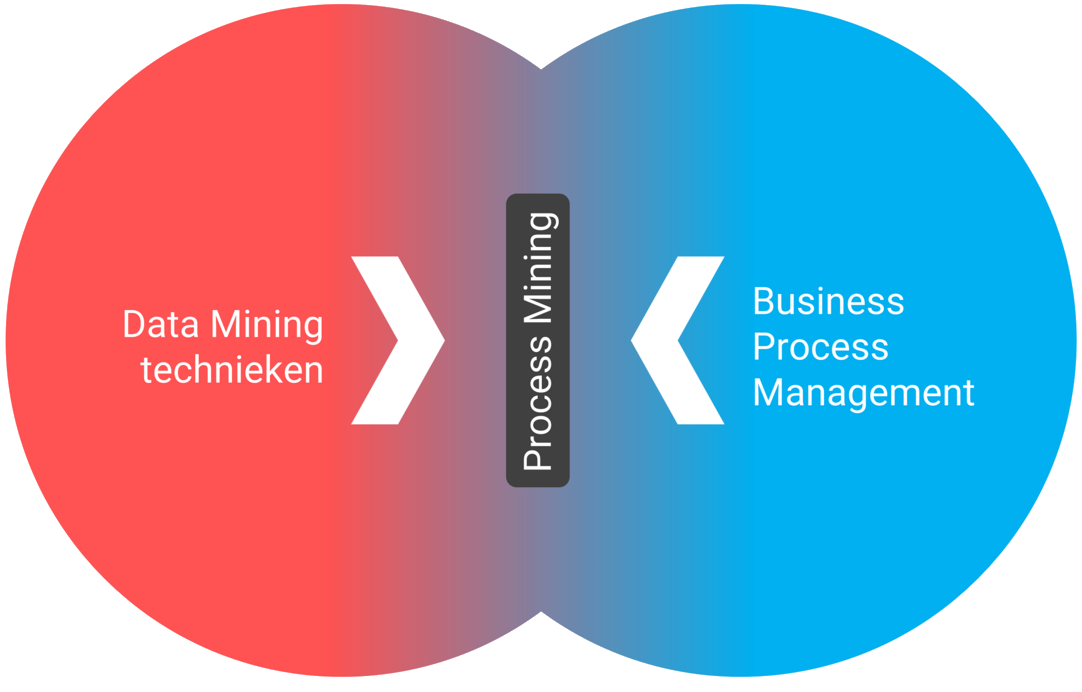
Figuur 2: Process Mining ligt op het snijvlak van Business Process Management (BPM) en data mining.
Dan nu enkele verschillen. Er bestaat een wezenlijk verschil en een overlap tussen data mining en process mining. Een eenvoudig voorbeeld verduidelijkt dit verschil.
- De focus bij data mining ligt nadrukkelijk op de patronen binnen de data. Zo probeert het Amerikaanse Pizza Hut bijvoorbeeld patronen in klantgedrag te ontdekken. Door artificial intelligence technieken in te zetten, wil het bedrijf klanten pizza’s aanbevelen op basis van het huidige weer en afhankelijk van de plek waar klanten wonen, of waar ze hun pizza willen verorberen. Een bepaald weerpatroon veronderstelt een bepaalde voorkeur voor een specifieke pizza.
- De focus bij process mining daarentegen ligt op de afwijkingen in het bedrijfsproces. Waarom wordt de pizza niet op tijd bij de klant bezorgd en hoe worden verschillen in de baktijd verklaard? Binnen process mining wordt onder meer gewerkt met event logs, audit trails en tijdstempels.
Een ander verschil is dat datamining van oudsher werkt met min of meer statische tabellen met data, terwijl process mining tegenwoordig ook in staat is om in realtime bedrijfsprocessen te monitoren. Bij data mining speelt bovendien het toeval een grote rol, terwijl je bij process mining ook een van tevoren gedefinieerd probleem kunt analyseren. Datamining zoekt nadrukkelijk naar correlaties en patronen, terwijl process mining zoekt naar causale verbanden. Of zoals het platform TechTarget het omschrijft:
Data mining is more concerned with the what – that is, the patterns themselves – while process mining seeks to answer the why.
Volg onze opleiding Process Mining om process mining te doorgronden en toe te passen in jouw situatie. Deze opleiding laat je kennismaken met de drie basisfuncties van Process Mining: ontdekken, conformeren en verbeteren.
Wat is text mining en hoe werkt het onder de motorkap?
Het vakgebied van data mining is aanzienlijk bekender dan dat van text mining, ook wel text analytics genoemd. Met de benoeming van prof. Jan C. Scholtes, de eerste hoogleraar Text mining in Nederland, kwam hier verandering in. In zijn oratie besteedde hij onder meer aandacht aan het verschil tussen data mining en text mining.
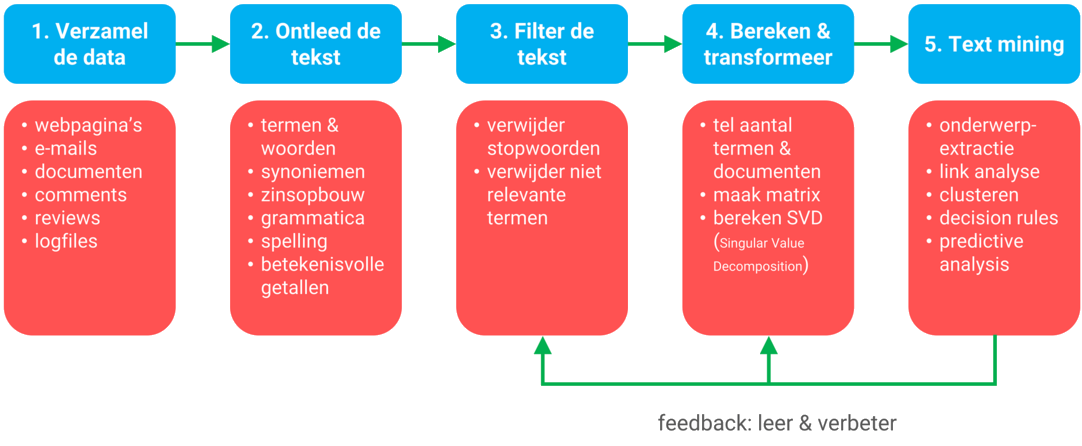
Figuur 3: De verschillende stappen in het text mining proces
Data mining is volgens Scholtes het analyseren van transactiegegevens die in relationele databases zitten. Denk aan creditcardbetalingen of pintransacties. Aan dergelijke transacties kan men diverse aanvullende kenmerken meegeven: datum, locatie, leeftijd van de kaarthouder, salaris, enzovoorts. Door deze gegevens te combineren kun je patronen in interesses of gedrag blootleggen.
Bij text mining ga je door geautomatiseerde analyse van ongestructureerde informatie relevante patronen en kenmerken ontdekken. Vervolgens kun je daarmee beter zoeken, data dieper analyseren en sneller inzichten boven tafel krijgen die anders vaak voor het blote oog verborgen blijven. Sinds een aantal jaar kan AI ook teksten genereren: generatieve AI.
Het idee van data mining is eigenlijk simpel maar het aantal valkuilen is groot. Het is in essentie een samenspel van vier vlakken: mens, organisatie, technologie en data. En op alle vlakken zul je gaan merken dat er kleine en grote hobbels te nemen zijn.
Het data mining proces
Als het gaat om het inrichten van je data mining proces of het maken van een data mining process diagram, kun je bijna niet om de zogenoemde CRISP-DM standaard heen. Sinds eind jaren negentig geldt dit de facto als een norm die breed is geaccepteerd voor data mining.
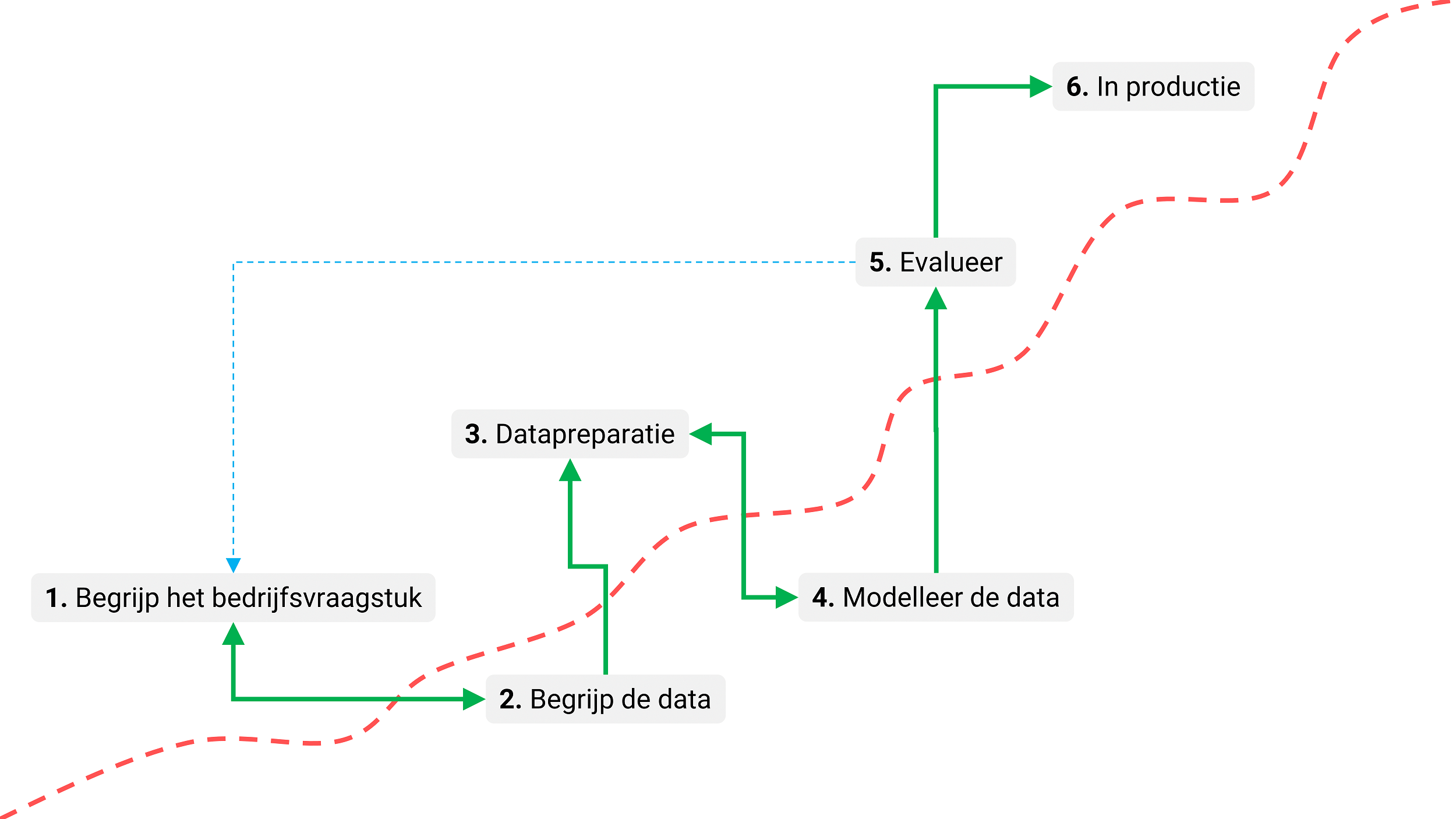
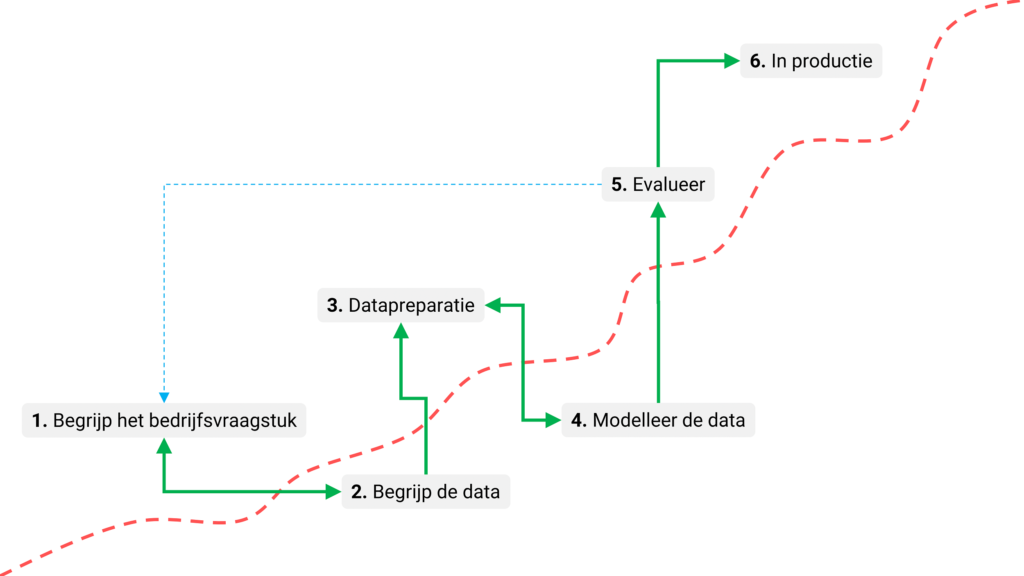
Figuur 4: Het Cross-industry standard process for data mining (CRISP-DM)
Het CRISP-DM protocol is niet gebouwd op een theoretisch, academisch fundament of gebaseerd op puur technische principes, maar is geënt op de dagelijkse praktijk. De standaard is niet vanuit een ivoren toren ontwikkeld, maar beschrijft uitvoerig in zes overzichtelijke stappen hoe je datamining projecten het beste kunt uitvoeren.
- Doorgrond de business vraag: tijdens deze eerste stap ga je de doelstellingen van het data mining project helder formuleren en de eisen vanuit een businessperspectief vertalen. Het resultaat is een probleemstelling en een voorlopig plan van aanpak gericht op doelrealisatie. Hier speelt de business consultant een cruciale rol.
- Begrijp de data: de tweede stap van data mining staat in het teken van het verzamelen van de data. Je ontplooit verder activiteiten die erop gericht zijn om helemaal vertrouwd te raken met de data. Je herkent datakwaliteitsproblemen, je bent alert op mogelijke biases in de data en verwerft de eerste inzichten. Je ontdekt interessante subsets van data en formuleert hypotheses over verborgen informatie.
- Prepareer de data: op basis van de eerste ruwe data werk je toe naar een definitieve dataset die als input zal dienen voor het data mining model. Je voert verschillende voorbereidende taken uit, zoals de selectie van tabellen, records en attributen, en het transformeren en opschonen van data. De taken herhaal je zo nodig in een willekeurige volgorde. Deze stap is typisch een gezamenlijke verantwoordelijkheid van de data analist en de data engineer.
- Modelleer de data: in deze fase worden verschillende algoritmes geselecteerd en toegepast om te komen tot een data mining model. Je kalibreert de parameters in de richting van optimale waarden, dit noemen we de trainingsfase. Tijdens het trainen modelleer je feitelijk de gewenste outputdata en de weg er naar toe. Doorgaans zijn er verschillende algoritmes voor hetzelfde data mining probleem. Sommige stellen specifieke eisen aan de vorm van de data. Daarom is het vaak nodig terug te keren naar de fase 3 van datapreparatie. De data scientist maakt het model.
- Evalueer het data mining model: het is nu zaak het model stap voor stap grondig te valideren en te evalueren. Weet je zeker dat je met dit model de bedrijfsdoelen gaat realiseren of is herziening noodzakelijk? Is de performance van het model toereikend voor het doel dat je hebt gesteld? Heb je geen belangrijke zaken over het hoofd gezien? Uiteindelijk neem je een besluit over het gebruik van de dataminingresultaten.
- Implementeer het model in productie: meestal is het de gebruiker, en niet de data-analist, die de implementatiestappen uitvoert. Maar zelfs als de analist de implementatie toch uitvoert, is het belangrijk voor de gebruiker om van tevoren te begrijpen welke acties hij moet uitvoeren om daadwerkelijk gebruik te kunnen maken van het data mining model. Afhankelijk van de vereisten kan de implementatiefase zo eenvoudig zijn als het genereren van een klantrapport waar bijvoorbeeld een voorspelling op staat of de klant het contract gaat verlengen, of zo complex als het implementeren van een herhaalbaar data mining proces in een specifieke stap in een bedrijfsproces.
De implementatie van het model betekent over het algemeen niet het einde van het project. Zelfs als het doel van het model is om puur je kennis van de data te vergroten, zul je de opgedane kennis moeten organiseren en presenteren op een manier die je collega’s kunnen gebruiken. Maar vaak gaat het om het toepassen van “live” modellen binnen de besluitvormingsprocessen van een organisatie, bijvoorbeeld het personaliseren van webpagina’s in realtime of het herhaaldelijk scoren van nieuwe leads in de marketingdatabase. Eén ding is zeker, met een goed ontworpen en goed gevuld datawarehouse kun je veel sneller de vruchten van data mining plukken.
De training R & data mining Tijdens de training R & data mining maak je in 3 intensieve dagen kennis met het vakgebied Analytics, data mining, text mining, en de basisprincipes van AI. Ook het Big Data concept, privacy en ethiek komen natuurlijk langs, maar je leert vooral programmeren in R met de beschikbare bibliotheken. In deze cursus leer je diverse complexere analyses met verschillende algoritmes op te zetten.
Tijdens de training R & data mining maak je in 3 intensieve dagen kennis met het vakgebied Analytics, data mining, text mining, en de basisprincipes van AI. Ook het Big Data concept, privacy en ethiek komen natuurlijk langs, maar je leert vooral programmeren in R met de beschikbare bibliotheken. In deze cursus leer je diverse complexere analyses met verschillende algoritmes op te zetten.9 voorbeelden van data mining
 De data mining voorbeelden of praktische use cases liggen sinds de opkomst in de jaren negentig van de vorige eeuw bij wijze van spreken voor het oprapen. Organisaties lopen er vanwege concurrentiegevoeligheid alleen lang niet altijd mee te koop. Het meest aansprekende data mining voorbeeld is ongetwijfeld afkomstig uit de filmklassieker MoneyBall, data mining zette de traditionele baseballwereld op zijn kop. In de omvangrijke reeks artikelen en boeken zijn een aantal klassieke use cases van data mining toegepast in het bedrijfsleven en de overheid inmiddels goed gedocumenteerd. We vatten enkele toepassingen hieronder kort samen:
De data mining voorbeelden of praktische use cases liggen sinds de opkomst in de jaren negentig van de vorige eeuw bij wijze van spreken voor het oprapen. Organisaties lopen er vanwege concurrentiegevoeligheid alleen lang niet altijd mee te koop. Het meest aansprekende data mining voorbeeld is ongetwijfeld afkomstig uit de filmklassieker MoneyBall, data mining zette de traditionele baseballwereld op zijn kop. In de omvangrijke reeks artikelen en boeken zijn een aantal klassieke use cases van data mining toegepast in het bedrijfsleven en de overheid inmiddels goed gedocumenteerd. We vatten enkele toepassingen hieronder kort samen:
- Supermarktketens en webwinkels gebruiken data mining methoden zoals associatieve technieken om achter consumentenpatronen te komen: welke artikelen worden bijvoorbeeld vaak tegelijkertijd gekocht.
- Binnen het kader van precisielandbouw en zogenoemde smart farming worden onder meer weerpatronen en data over gewasgroei en bemesting geanalyseerd met behulp van data mining technieken.
- Waarom slijt een specifiek machineonderdeel veel sneller dan andere onderdelen? In fabrieken wordt data mining ingezet om bepaalde patronen en fouten in het fabricageproces te ontdekken en preventief onderhoud te voorspellen.
- Misbruik en fraude in de gezondheidszorg komen aan het licht als je data mining software gebruikt en op zoek gaat naar afwijkende patronen in patiëntengedrag, medicijngebruik, declaratiegedrag en deze vergelijkt met de protocollen.
- Door in ziekenhuizen op grote schaal data mining en big data analytics in te zetten, komen patronen in ziektebeelden en erfelijke ziekten vrij snel aan het licht. Dit kan de kwaliteit van zorg op termijn op een hoger plan tillen.
- Data mining algoritmes signaleren fraude in de financiële dienstverlening door (afwijkende) patronen te signaleren in betaalgedrag en menselijk gedrag.
ICS: een schoolvoorbeeld van data mining
 Data mining heeft al veel organisaties en bedrijven geholpen om slimmer te werken. De case van International Card Services (ICS) is misschien niet het allerbekendste voorbeeld maar wel een erg fraai voorbeeld. Elke stap van het proces, van nieuwe klanten binnenhalen tot klanten behouden, van acceptatie tot het stimuleren van het gebruik van creditkaarten, is onderbouwd met data mining-algoritmes. Deze vergroten de effectiviteit van de processtappen enorm. Zo daalde het aantal frauduleuze transacties in een jaar tijd met maar liefst 50% en nam het gebruik van de kaarten met 20% toe. Niet alleen ICS had hier belang bij, maar ook de klant. Lees hier het juryrapport dat inzage geeft in de intelligence bij ICS.
Data mining heeft al veel organisaties en bedrijven geholpen om slimmer te werken. De case van International Card Services (ICS) is misschien niet het allerbekendste voorbeeld maar wel een erg fraai voorbeeld. Elke stap van het proces, van nieuwe klanten binnenhalen tot klanten behouden, van acceptatie tot het stimuleren van het gebruik van creditkaarten, is onderbouwd met data mining-algoritmes. Deze vergroten de effectiviteit van de processtappen enorm. Zo daalde het aantal frauduleuze transacties in een jaar tijd met maar liefst 50% en nam het gebruik van de kaarten met 20% toe. Niet alleen ICS had hier belang bij, maar ook de klant. Lees hier het juryrapport dat inzage geeft in de intelligence bij ICS.
huur een data mining expert in
- In de telecom wordt een data mining model al decennialang toegepast om patronen in belgedrag en het switchgedrag van klanten te analyseren met als doel ze langer aan zich te binden.
- Data mining software wordt bij de overheid ingezet om uitkeringspatronen en de belastingmoraal van burgers te monitoren en te analyseren.
- Binnen de openbare ruimte zetten overheden de software in om patronen te ontdekken in het kader van crowd control, verkeersregulatie en criminaliteitspreventie.
Let er op dat wanneer je wil gaan werken met persoonsgegevens of wanneer je geavanceerde data mining modellen wil gaan toepassen, dat je aan de privacywetgeving (AVG) en de nieuwe AI Act voldoet. Zie ook ons artikel ‘De 9 grootste trends in Artificial Intelligence, Big Data & BI voor 2026’.
Het handboek Artificial Intelligence  In dit complete Artifical Intelligence-boek - al meer dan 25.000 exemplaren verkocht - komt het totale spectrum van data analyse, data mining en AI aan bod. Met als doel: veel betere beslissingen nemen en het intelligenter maken van je organisatie. Het geeft je een perfect kader om het grotere geheel (BI, AI & Data Science) structureel vorm te geven en te implementeren.
In dit complete Artifical Intelligence-boek - al meer dan 25.000 exemplaren verkocht - komt het totale spectrum van data analyse, data mining en AI aan bod. Met als doel: veel betere beslissingen nemen en het intelligenter maken van je organisatie. Het geeft je een perfect kader om het grotere geheel (BI, AI & Data Science) structureel vorm te geven en te implementeren.
Verschillende soorten data mining tools
 Alle grote enterprise softwareleveranciers zoals SAP, Oracle en IBM, bieden verschillende data mining software tools aan. Ook de in Business Intelligence gespecialiseerde softwareleveranciers bieden dergelijke tools aan. Voor een actueel, vergelijkend warenonderzoek van data mining software leveranciers raadpleeg je de Business Intelligence & Data Analytics Guide™ 2026. Richt je daarbij vooral op de onderdelen Analytics, Artificial Intelligence en Big Data.
Alle grote enterprise softwareleveranciers zoals SAP, Oracle en IBM, bieden verschillende data mining software tools aan. Ook de in Business Intelligence gespecialiseerde softwareleveranciers bieden dergelijke tools aan. Voor een actueel, vergelijkend warenonderzoek van data mining software leveranciers raadpleeg je de Business Intelligence & Data Analytics Guide™ 2026. Richt je daarbij vooral op de onderdelen Analytics, Artificial Intelligence en Big Data.
Je hoeft overigens niet altijd je portemonnee te trekken. Je kunt ook gebruik maken van open source programmeertalen zoals Python, R, Java, Scala, Julia, RapidMiner en SAS. Sommige leveranciers zijn gespecialiseerd in bepaalde onderdelen zoals text mining of in bepaalde data mining technieken zoals classificatie, clustering, regressie, associatie en het signaleren van outliers (uitschieters). Hoe dan ook, het herkennen van patronen in datasets staat centraal.
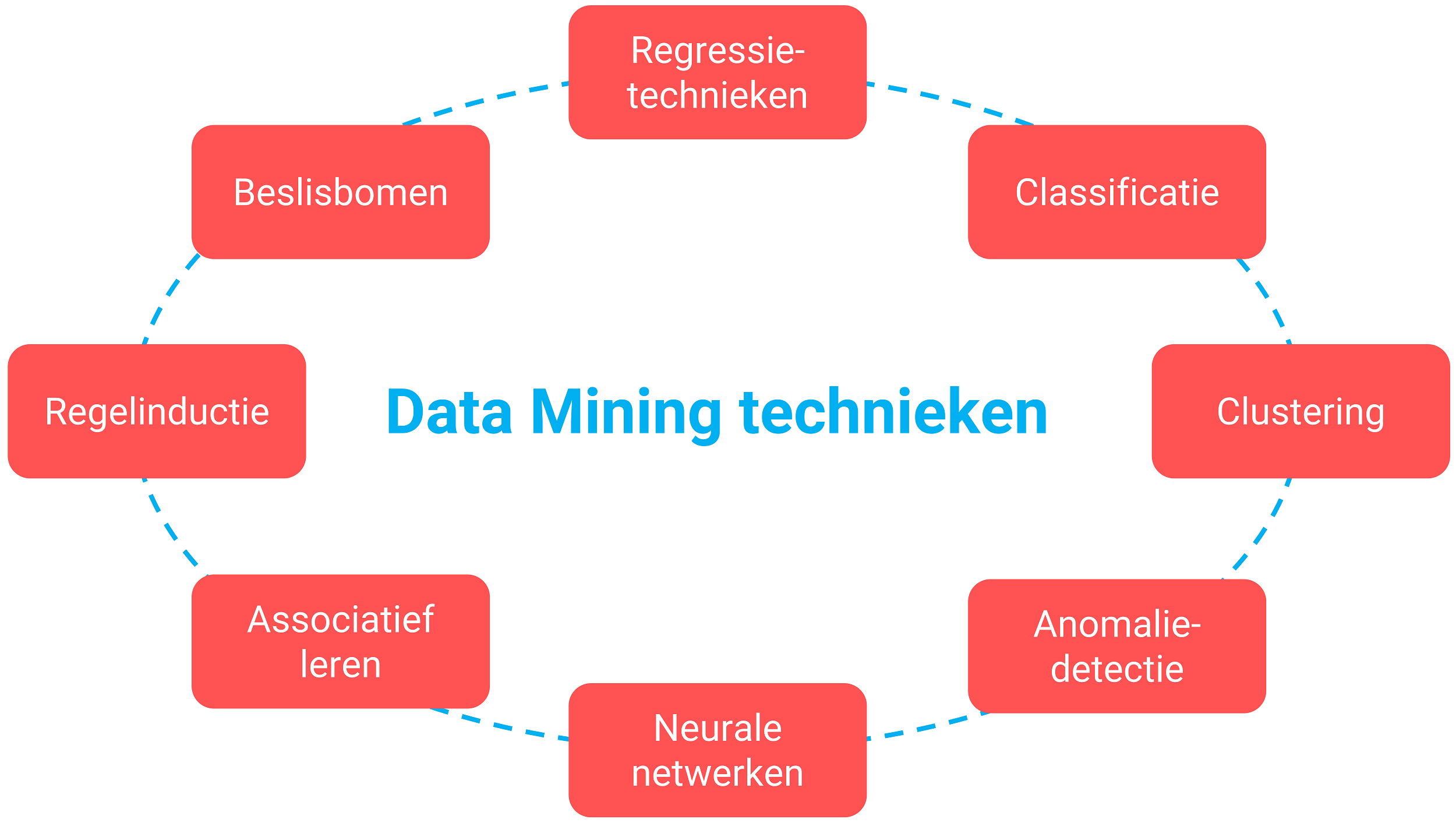
Figuur 5: Verschillende technieken die data mining software tools zouden moeten ondersteunen.
Als we de leveranciers mogen geloven worden data mining tools ook steeds gebruiksvriendelijker. De aanbieders claimen dat gebruikers zonder enige programmeerervaring ook aansprekende resultaten kunnen boeken met data mining software. Claims als “no code” of “low code” en drag and drop-functionaliteit zouden die gebruiksvriendelijkheid onder meer bevorderen. Sommige data mining software leveranciers zijn gespecialiseerd in een bepaalde sector, bijvoorbeeld de landbouw, industrie of het onderwijs. Specifieke marktkennis bij de softwareleverancier kan behulpzaam zijn bij het snel doorgronden van jouw bedrijfsprobleem dat je wilt gaan oplossen met een data mining tool.
De vijf regels voor de selectie van data mining software
 Aanbieders van data mining software adverteren soms met exotische termen als “predictive data mining software” of “data mining predictive analytics” om zo hun scope te verbreden en hun marktexposure optisch te vergroten. Het ontbreken van heldere definities in het producten- en dienstenportfolio van leveranciers maakt de markt voor data mining echter minder transparant, vertroebelt inhoudelijke discussies en verstoort een ordentelijk, objectief proces voor het selecteren van leveranciers en tools. Duidelijke definities helpen om de juiste leverancier en data mining tool te selecteren waarmee je jouw specifieke bedrijfsprobleem kunt oplossen. De volgende vijf regels voor zakendoen met de softwareleveranciers kunnen je behoeden voor een flater of miskoop:
Aanbieders van data mining software adverteren soms met exotische termen als “predictive data mining software” of “data mining predictive analytics” om zo hun scope te verbreden en hun marktexposure optisch te vergroten. Het ontbreken van heldere definities in het producten- en dienstenportfolio van leveranciers maakt de markt voor data mining echter minder transparant, vertroebelt inhoudelijke discussies en verstoort een ordentelijk, objectief proces voor het selecteren van leveranciers en tools. Duidelijke definities helpen om de juiste leverancier en data mining tool te selecteren waarmee je jouw specifieke bedrijfsprobleem kunt oplossen. De volgende vijf regels voor zakendoen met de softwareleveranciers kunnen je behoeden voor een flater of miskoop:
- Trap niet in de bekende verkooptrucjes: softwareleveranciers werken vaak met verschillende basis- en premiumversies. Text mining is dan bijvoorbeeld alleen te gebruiken als je een premium versie aanschaft. Wees daarop bedacht.
- Gebruik je onderhandelingsmacht: realiseer je dat softwareleveranciers bijna altijd bereid zijn kortingen te geven, zeker bij de aanschaf van grote aantallen licenties. Verkopers van data mining software moeten immers ook kun targets halen. Zogenoemde street prices wijken altijd af van de officiële list prices of brochureprijzen.
- Wees kritisch op het aantal licenties: bedenk dat aan elke extra module, functionaliteit of feature meestal ook een prijskaartje hangt. Niet elke gebruiker van data mining software hoeft altijd over alle functionaliteiten en plug-ins te beschikken. Besparen op licentiekosten is altijd een optie.
- Pas op voor scherpe aanbiedingen: er is een flink aantal aanbieders op de markt die zogenaamde gratis versies van datamining software, Nederlandstalig soms, aanbieden. Hoewel dit in eerste instantie aantrekkelijk lijkt, moet je altijd bedacht zijn dat hierachter toch meestal wel abonnementsmodel schuil gaat dat loopt via upgrades naar premium versies.
- Haal het maximale uit je investering: bedenk dat een goede documentatie van de data mining software heel belangrijk is en die is bij gratis versies niet altijd op orde. Maar dan nog: data mining leer je niet uit een boekje. Oefening baart kunst. Volg daarom een relevante, ondersteunende cursus. De Passionned Academy verzorgt bijvoorbeeld de training R & Data Mining, waarbij je ook zelf aan de knoppen zit.
Een Data Mining consultant inhuren
Er valt veel voor te zeggen om bij een eerste of tweede project een ervaren data mining consultant in te huren. Deze consultants werken vaak op meerdere projecten bij verschillende opdrachtgevers in allerlei sectoren en zo trek je in één keer veel kennis en ervaring naar binnen. Zie figuur 6.
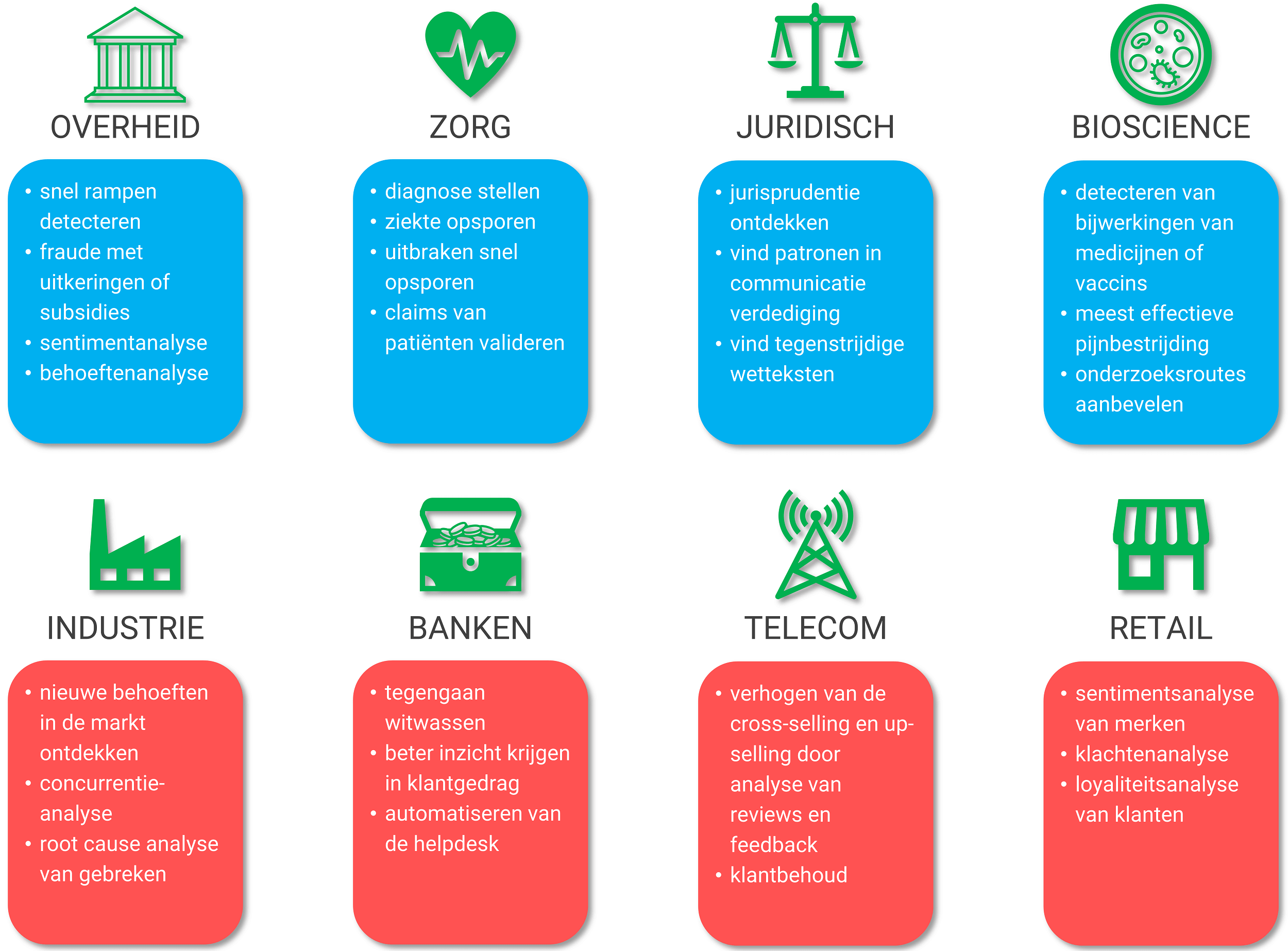
Figuur 6: Een goede data mining consultant brengt ervaring met use cases uit diverse sectoren met zich mee.
Een data mining consultant heeft niet dezelfde specifieke technische kennis en vaardigheden (en niveau) als een data scientist maar heeft juist een afgewogen mix van kennis van verschillende domeinen zoals organisatiekunde, bedrijfskunde, procesmanagement, IT en machine learning.
Maak van data mining een succes: 6 tips
 Veel data mining projecten komen niet eens in productie en dat is onzettend jammer. En dat ligt vaak niet aan de technologie. De organisatorische kant wordt bijvoorbeeld compleet genegeerd of de communicatie met de gebruikers wordt verwaarloosd. Het project is puur technologiegedreven of er bestaan vanuit het management onrealistische verwachtingen over de technologie. Meestal gaan die samen. Houd de volgende adviezen altijd op je netvlies:
Veel data mining projecten komen niet eens in productie en dat is onzettend jammer. En dat ligt vaak niet aan de technologie. De organisatorische kant wordt bijvoorbeeld compleet genegeerd of de communicatie met de gebruikers wordt verwaarloosd. Het project is puur technologiegedreven of er bestaan vanuit het management onrealistische verwachtingen over de technologie. Meestal gaan die samen. Houd de volgende adviezen altijd op je netvlies:
- Hanteer het CRIPS-DM model en volg nauwgezet de 6 stappen
- Wees zeer alert op de datakwaliteit, die kan het project maken of breken
- Stel een multidisciplinair team samen met vertegenwoordigers van business en ICT
- Zorg dat in het team voldoende kennis van en ervaring met data mining aanwezig is
- Verzamel zoveel mogelijk relevante gegevens, beperk je niet tot interne data
- Selecteer het juiste type algoritme passend bij het probleem / vraagstuk
Wil je een uitgebreide toelichting bij deze tips? Neem dan contact met ons op voor meer informatie.
Verdiep je verder in data mining
 We hebben nog lang niet alle aspecten, details en geheimen van data mining onthult. Wil je nog veel meer weten over dit mooie vakgebied? Zoek dan hier de verdieping, lees de volgende artikelen:
We hebben nog lang niet alle aspecten, details en geheimen van data mining onthult. Wil je nog veel meer weten over dit mooie vakgebied? Zoek dan hier de verdieping, lees de volgende artikelen:
Door veel meer kennis over data mining op te doen, verminder je het risico om te falen enorm. Zie ook onze tips voor succes.
Wil je ook aan de slag met data mining?
Wil je meer informatie over de inzet van een of meer data mining consultants of overweeg je om onze training Data mining in R te volgen? Ons team van onafhankelijke adviseurs, docenten en ervaren consultants staat voor je klaar. Neem gerust contact met ze op en wij helpen je graag verder voorwaarts.
Over Passionned Group
Veelgestelde vragen
Is Data Mining iets heel anders dan Artificial Intelligence?In grote lijnen zijn deze twee technieken goed vergelijkbaar en maken ze vaak gebruik van precies dezelfde algoritmes en modellen. Allebei stellen ze je in staat om geautomatiseerde analyses uit te voeren. Maar het vakgebied AI is meer omvattend en kan bijvoorbeeld ook analyses uitvoeren op teksten, afbeeldingen, video's en geluidsfragmenten. Gewoonlijk gebruik je data mining om gestructureerde gegevens te analyseren en text mining voor ongestructureerde data zoals teksten.
Hoeveel gegevens heb je nodig voor data mining?
In principe kun je ook uit heel kleine, beperkte datasets (minder dan 1.000 rijen en een paar kolommen) interessante patronen halen en nieuwe inzichten verkrijgen. Belangrijk is natuurlijk of de resultaten statistisch significant zijn. Maar wil je echt verfijnde kennis blootleggen die verborgen zit in de data dan heb je veel grotere datasets (meer dan 10.000 rijen en veel kolommen) nodig om betrouwbare resultaten te genereren. Zo kan je een eenvoudige beslisboom maken met een kleine dataset en een uitgebreidere met een grote, meer gedetailleerde dataset. Een uitgebreidere beslisboom bevat meer kennis en heeft daardoor meer waarde.
Kan data mining voorspellen?
Ja, met data mining kun je niet alleen classificeren (dit gaat om een rode auto) en clusteren (alle roodkleurige auto's bij elkaar zetten) maar ook voorspellingen doen. Bijvoorbeeld wat de kans is dat een klant een rode auto gaat kopen of zijn leasecontract gaat verlengen.
Hoe belangrijk is goede datakwaliteit?
Heel belangrijk, het succes van data mining staat of valt met goede datakwaliteit. Verdiep je hier verder in het verbeteren van datakwaliteit.
Hoe kom ik er achter of er biases in mijn data zitten?
Dit is nog niet zo eenvoudig. Er zijn namelijk veel aspecten die voor het ontdekken van biases relevant kunnen zijn. Denk hierbij aan data entry, de inrichting van workflows, selectie aan de poort, KPI's die perverse prikkels met zich meebrengen, de manier van datamodellering, et cetera. Ons advies is om een onderzoek uit te laten voeren door een data mining expert. Daarnaast kun je zelf ook het een en ander doen: praat met de mensen die de gegevens invoeren, kijk een tijdje met ze mee en voer ook een procesanalyse uit.




