Trek de regie naar je toe met onze unieke Data Science training

Deze 10-daagse opleiding Data Science is bedoeld voor iedereen die vanuit een business perspectief succesvol wil zijn met data science en daarnaast zijn of haar carrière op een hoger niveau wil tillen. Er is namelijk een groot tekort aan managers & adviseurs die data science, machine learning en artificial intelligence (AI) integraal kunnen toepassen. Daarbij leg je niet de nadruk op de techniek, maar juist op het bedrijfsmatige, organisatorische en menselijke perspectief.
Download de brochure Bekijk data & schrijf in
In deze interactieve, praktijkgerichte data science training (HBO+) komen alle facetten aan bod die jou als data science-translator, consultant, adviseur of (project)manager helpen om data science, (generatieve) AI en machine learning met succes toe te passen in jouw organisatie. In 10 intensieve en interactieve dagen stomen we je klaar voor een leidende positie in jouw organisatie. Voor meer informatie download je hier de uitgebreide brochure of neem je hier contact met ons op.
Focus ligt naast de techniek ook op de business-kant
Natuurlijk leer je alle belangrijke technische aspecten in deze opleiding Data Science & AI. Zo kijken we uitgebreid naar geavanceerde technologie zoals machine learning, deep learning, meta learning, reinforcement learning, Large Language Models (LLM’s) en de algoritmes waarmee je AI-modellen kunt bouwen. Ook leggen we de werking uit van Generative Pre-Trained Transformers (GPT), Diffusion Models en Generative Adversarial Networks (GAN’s). Maar tijdens onze Data Science opleiding gaan we vooral aan de slag met de veranderkundige en bedrijfskundige perspectieven:
- Hoe zet je Data Science en AI op de kaart in jouw organisatie? Welke businesscase kun je maken?
- Hoe ga je een AI-first strategie ontwikkelen en zorgen dat iedereen in je organisatie daaraan meewerkt?
- Hoe zorg je dat je AI-technologie kan inbedden in de juiste Business Intelligence processen en kaders?
- Welke algoritmes en methodieken voor patroonherkenning kun je gebruiken?
- Hoe bouw je een robuuste, toekomstbestendige data-infrastructuur?
- Welke specifieke toepassingen kun je bedenken voor generatoren zoals ChatGPT, Bard, LaMDA, DALL-E, Midjourney en DreamStudio?
- Waar moet je op letten bij de implementatie van machine learning (supervised, unsupervised), deep learning en generatieve AI?
- Welke AI-tools zijn beschikbaar en welke past het beste bij jouw specifieke probleem?
- Hoe implementeer je succesvol een big data-oplossing en een data lake en wat komt daarbij zoal kijken?
- Wat is de relatie tussen innovatie, nieuwe business modellen, machine learning en data science en hoe ga je die optimaliseren?
- Hoe ga je om met interne politiek, draagvlak in de organisatie en acceptatie bij de gebruikers?
Deze complete, praktijkgerichte Data Science training met maar liefst 24 modules en een uitdagende eindopdracht is een absolute aanrader voor iedereen die zich wil bekwamen in data science, artificial intelligence en big data. En zeker aan te bevelen wanneer je daadwerkelijk successen wilt boeken op weg naar een datagedreven organisatie.
Praktische informatie: locatie, duur, data en prijs
Duur: 10 dagen
Data: 5 maart t/m 5 juni 2026,1 oktober t/m 18 december 2026
Prijs: € 6.500
Zet de juiste stappen met onze Data Science opleiding
Tijdens 10 intensieve dagen word je op een positieve manier ondergedompeld in het vakgebied en klaargestoomd voor een leidende positie in jouw organisatie. Eerdere deelnemers aan deze opleiding bleken bij uitstek geschikt om de juiste stappen te zetten in nieuwe of lopende Data Science-trajecten in hun organisatie.
Overzicht van de 24 modules
Deze complete Data Science opleiding (HBO+ niveau) bestaat uit 24 praktijkgerichte, compacte modules:
✪ KPI’s, analytics & machine learning
✪ Data Science volwassenheid en AI-first
✪ Projectmanagement & governance
✪ Datavisualisatie & data storytelling
✪ Succesfactoren van BI & Data Science
✪ Introductie datawarehousing & big data
✪ Datawarehouse architectuur & data lakes
✪ Het datawarehouse & de ETL-processen
✪ Business Intelligence & Data Analytics
✪ Master Data (MDM) en metadata
✪ Beheer van datawarehouses en data lakes
✪ Datakwaliteit verbeteren & AI
✪ Continu verbeteren van (big) data
✪ AI, big data science & machine learning
✪ De business case & generatieve AI
✪ Ontwerpen van een AI architectuur
✪ Algoritmes en machine learning technieken
✪ Data science tools & talen
✪ Kennismaken met Python, notebooks en R
✪ Machine learning modellen ontwikkelen
✪ Privacy, ethiek en wetgeving
✪ Vaardigheden en competenties
Er is ruimte voor maximaal 16 deelnemers, zorg daarom dat je tijdig boekt, zodat je verzekerd bent van een plaats.
Dé training voor een AI-first organisatie
De datagedreven maatschappij en de bijbehorende algoritmisering is inmiddels een “fact of life”. Diverse nationale en internationale denktanks en wetenschappers zijn het er allemaal over eens dat het juist inzetten van data en algoritmes hét verschil gaat maken tussen krimp of groei. Met de komst van ChatGPT, Bard en Microsoft CoPilot zien we nog meer disruptie op ons afkomen. Elke sector en elk beroep gaat hiermee te maken krijgen. Kortom: onze Data Science opleiding is bedoeld voor organisaties die te maken hebben met complexe data-uitdagingen en substantieel slimmer willen worden.
Je leert data analytics, machine learning en meer…
 De intelligentie van een organisatie laat zich niet vangen in louter data analytics en machine learning. Het concept gaat veel verder. In ons praktische model leer je waar en hoe data science, AI, business intelligence, datagedreven werken en de intelligente organisatie elkaar raken en waarom een analytische bedrijfscultuur van groot belang is voor het slagen van data science en artificial intelligence.
De intelligentie van een organisatie laat zich niet vangen in louter data analytics en machine learning. Het concept gaat veel verder. In ons praktische model leer je waar en hoe data science, AI, business intelligence, datagedreven werken en de intelligente organisatie elkaar raken en waarom een analytische bedrijfscultuur van groot belang is voor het slagen van data science en artificial intelligence.
Tijdens deze data science opleiding maak je kennis met alle noodzakelijke elementen om Data Science succesvol te koppelen aan het verbeteren van de decision making in jouw organisatie.
10-daags programma van de Data Science training
Tijdens deze Data Science training kom je in aanraking met alle aspecten van het vakgebied. Je leert datavraagstukken om te zetten in resultaten voor jouw organisatie. Naast de technische aspecten (zoals Internet of Things, supervised en unsupervised machine learning, deep learning, generatieve AI, neurale netwerken, data lakes, et cetera) maak je kennis met alle relevante business-aspecten. Denk dan aan projectmanagement, risico’s, valkuilen, businesscases, KPI’s, governance en datakwaliteit, data governance en privacy- en ethische principes.
DATA SCIENCE DINNER: Introductie van de Data Science opleiding
 Het diner op de avond voorafgaand aan de start van deze opleiding is inmiddels uitgegroeid tot een traditie. Het is een onmisbare en aangename opwarmer voor je totale opleidingstraject. Daan van Beek, eindbaas van Passionned Group en auteur van het managementboek ‘De intelligente, datagedreven organisatie’ is jouw gastheer die avond.
Het diner op de avond voorafgaand aan de start van deze opleiding is inmiddels uitgegroeid tot een traditie. Het is een onmisbare en aangename opwarmer voor je totale opleidingstraject. Daan van Beek, eindbaas van Passionned Group en auteur van het managementboek ‘De intelligente, datagedreven organisatie’ is jouw gastheer die avond.
Hij geeft je een overzicht van wat je kunt verwachten van deze training. Tussen de verschillende gangen van het dinner is er voldoende ruimte voor interactie, verhalen en discussie over algoritmes en de economische betekenis en de maatschappelijke impact van deze megatrend.
DAG 1: Introductie data science, trends, KPI’s & AI-first strategie
 Je maakt tijdens de eerste dag van deze Data Science opleiding kennis met de kracht van datagedreven organisaties en AI. Je gaat niet alleen KPI’s, big data en machine learning beter begrijpen, maar krijgt ook inzicht in de laatste trends in data science, AI en de voordelen van analytics. Je leert daarnaast welke stappen je moet zetten om een AI-first strategie te implementeren in jouw organisatie.
Je maakt tijdens de eerste dag van deze Data Science opleiding kennis met de kracht van datagedreven organisaties en AI. Je gaat niet alleen KPI’s, big data en machine learning beter begrijpen, maar krijgt ook inzicht in de laatste trends in data science, AI en de voordelen van analytics. Je leert daarnaast welke stappen je moet zetten om een AI-first strategie te implementeren in jouw organisatie.
DAG 2: Projectmanagement, datavisualisatie & data science succes
Deze dag van onze erg goed gewaardeerde Data Science opleiding start met projectmanagement & governance in data science. De resterende ondelen staan volledig in het teken van de gebruikers van algoritmes, dashboards en rapporten. Het complete data science-proces (alle 15 stappen) komt uitgebreid aan bod. Je leert ook hoe je de User eXperience van data kan verbeteren onder andere door effectieve datavisualisatie. Tot slot komen de 12 meest kritieke succesfactoren van data science, AI en BI langs.
MODULE 5: Processtappen en datavisualisatie
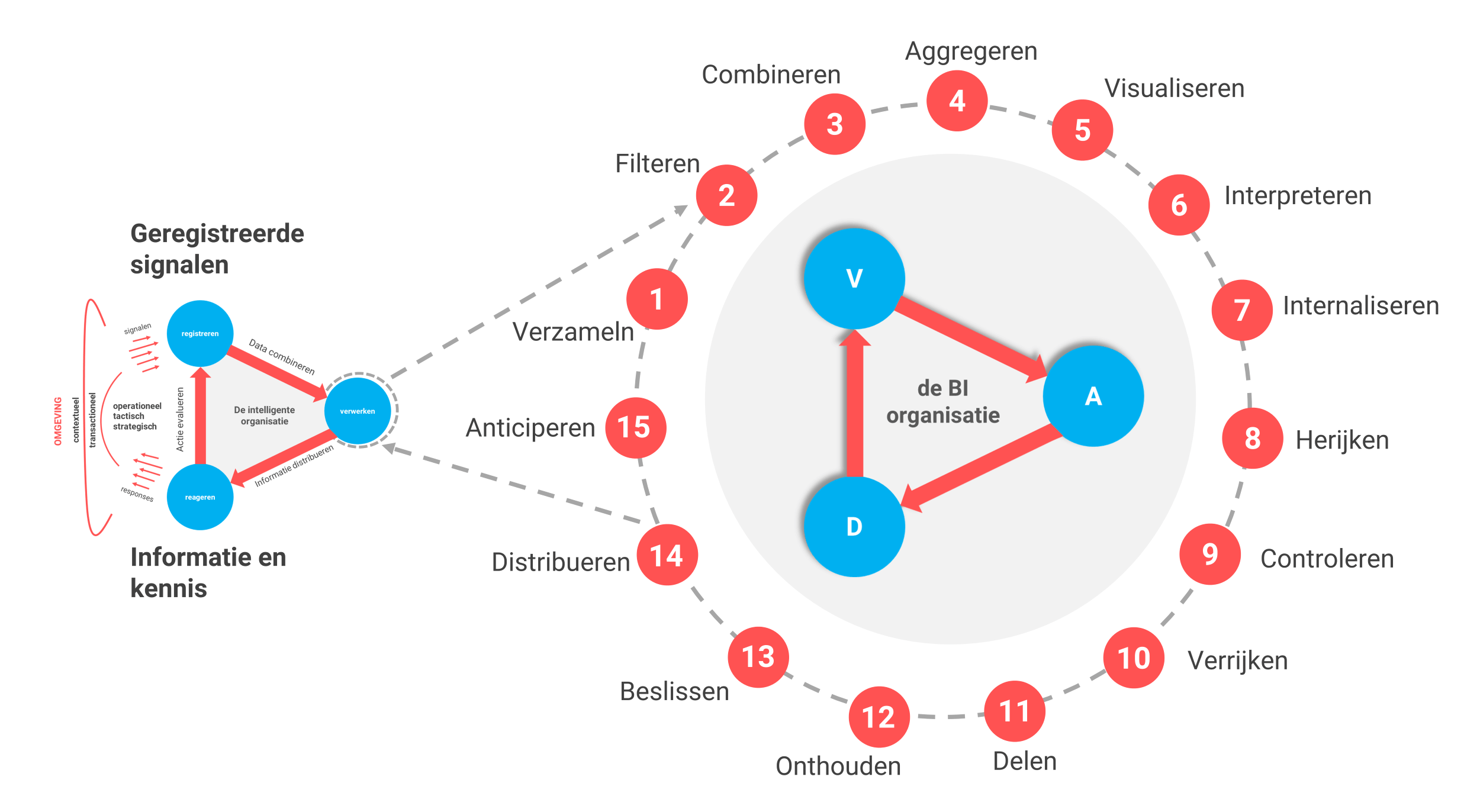
- BI en data science is een proces: je maakt gedetailleerd kennis met de 15 stappen voor verwerking, analyse, distributie van informatie, en vooral het effectief gebruik ervan voor het nemen van betere beslissingen. Daarnaast presenteert de docent waar het data science proces afwijkt van het BI proces.
- Datavisualisatie & User eXperience (UX): je maakt kennis met de meest krachtige datavisualisatietechnieken, data storytelling en leert hierdoor het gebruiksgemak van informatie te versterken. Je moet tevens rekening houden met de psychologische effecten en cognitieve kaders. Wat komt er bij effectieve big data-visualisatie kijken en met welke factoren moet je specifiek rekening houden? Inclusief een bespreking van de onthullende BBC-documentaire: ‘How to make better decisions’. In groepjes ga je oefenen met het vormgeven van verschillende effectieve datavisualisaties.
DAG 3: Datawarehouse, Data Lakes, Big Data & Architectuur
 Dag 3 van deze Data Science training is volledig gewijd aan het tot stand brengen van een solide data-infrastructuur en ETL-processen voor zowel een noodzakelijke datawarehouse omgeving als toekomstvaste big data opslagmethodieken. Een implementatie van een solide datawarehouse en een schoon data lake kan een Data Science-traject maken of breken, waar moet je allemaal op letten?
Dag 3 van deze Data Science training is volledig gewijd aan het tot stand brengen van een solide data-infrastructuur en ETL-processen voor zowel een noodzakelijke datawarehouse omgeving als toekomstvaste big data opslagmethodieken. Een implementatie van een solide datawarehouse en een schoon data lake kan een Data Science-traject maken of breken, waar moet je allemaal op letten?
DAG 4: Analytics, Master Data Management, metadata & beheer
De vierde dag van onze opleiding Data Science staat in het teken van: datawarehousegebruik in lijn met de hogere doelen van BI Analytics, de Business Intelligence tools en het beheer van een DWH, masterdata, meta data en open data. Big data en vooral AI neemt hier een steeds grotere plaats in.
DAG 5: Data governance, datakwaliteit en continu verbeteren


Data governance is onmisbaar voor organisaties die datagedreven willen werken. De totale levenscyclus van data – van ontstaan tot verwijdering – moet je dan als leerproces en feedbackloop gaan implementeren en borgen. Tijdens dag 5 van onze opleiding Data Science leer je hoe je een robuuste Data Governance-structuur opzet en wat daar zoal bij komt kijken.
DAG 6: Het ontwikkelen van AI, machine learning & AI-architectuur
Tijdens de 6e dag van deze opleiding Data Science kom je in aanraking met analytische en voorspellende modellen die de basis vormen voor (generatieve) AI en machine learning en bijbehorende architectuur.
DAG 7: Machine learning algoritmes: theorie en praktijk
 Tijdens de 7e dag van deze opleiding Data Science kom je in aanraking met de theorie, de technieken en de praktijk. Je gaat onder begeleiding van de trainer in een workshop zelf aan de slag met Python.
Tijdens de 7e dag van deze opleiding Data Science kom je in aanraking met de theorie, de technieken en de praktijk. Je gaat onder begeleiding van de trainer in een workshop zelf aan de slag met Python.
DAG 8: Data Science in de praktijk
Tijdens dag 8 van deze opleiding data science gaat de docent verder waar hij de vorige dag was gebleven. In een aantal workshops ga je aan de slag met machine learning en tekst mining en leer je zelf modellen te ontwikkelen, te trainen, te testen en te valideren.
DAG 9: Ethiek, privacy, vaardigheden en competenties
 Tijdens deze 9e opleidingsdag van de training Data Science gaan we in op de belangrijkste ethische principes en privacywetgeving. Tevens ga je leren welke vaardigheden en competenties nodig zijn om van data science een succes te maken.
Tijdens deze 9e opleidingsdag van de training Data Science gaan we in op de belangrijkste ethische principes en privacywetgeving. Tevens ga je leren welke vaardigheden en competenties nodig zijn om van data science een succes te maken.
DAG 10: Afsluitende opdracht en certificering
Gedurende de opleiding werk je in groepjes aan een uitdagende opdracht om te toetsen of je het geleerde in de praktijk kunt brengen. De opdracht lever je een week voor de laatste dag van deze data science opleiding in en presenteer je op deze dag. We bespreken de resultaten van de verschillende opdrachten integraal met elkaar door.
Streven naar dataperfectie versus adoptie
![]() Het voorbeeld van de Politie Amsterdam-Amstelland maakt duidelijk dat Data Science niet stopt bij de techniek. De eerste Data Science toepassingen bij de politie waren spraakmakend. De software stippelde voor de agenten dagelijks een route uit waar de kans het grootst was om een crimineel aan te treffen. Hoewel de agenten erg enthousiast leken over de oplossing, accepteerden ze deze aanvankelijk niet. Zij reden gewoon hun gebruikelijke eigen route door de stad zoals ze dat altijd gewend waren. Kortom: algoritmes ontwikkelen zonder rekening te houden met acceptatie door de eindgebruiker is vergelijkbaar met een superprofessionele mountainbike kopen maar er nooit op rijden. Inmiddels laten de agenten zich graag adviseren door het algoritme en is deze vorm van predictive policing met succes wereldwijd uitgerold.
Het voorbeeld van de Politie Amsterdam-Amstelland maakt duidelijk dat Data Science niet stopt bij de techniek. De eerste Data Science toepassingen bij de politie waren spraakmakend. De software stippelde voor de agenten dagelijks een route uit waar de kans het grootst was om een crimineel aan te treffen. Hoewel de agenten erg enthousiast leken over de oplossing, accepteerden ze deze aanvankelijk niet. Zij reden gewoon hun gebruikelijke eigen route door de stad zoals ze dat altijd gewend waren. Kortom: algoritmes ontwikkelen zonder rekening te houden met acceptatie door de eindgebruiker is vergelijkbaar met een superprofessionele mountainbike kopen maar er nooit op rijden. Inmiddels laten de agenten zich graag adviseren door het algoritme en is deze vorm van predictive policing met succes wereldwijd uitgerold.
Aanvullende informatie van deze training Data Science
De prijs van deze opleiding is inclusief het Data Science Dinner, lunchbuffet in het restaurant van het Berghotel Amersfoort, onbeperkt thee en koffie, overige drankjes en hapjes tijdens de breaks. Je ontvangt ook gratis een exemplaar van de boeken ‘De intelligente, datagedreven organisatie’ en ‘Datacratisch werken: kom in de verbetermodus met een datagedreven PDCA’ van Daan van Beek.
✪ vrijgesteld van BTW
✪ Studiebelasting: max. 15-20 uur
✪ gewaarmerkt digitaal certificaat
✪ van 9:00 tot 17:00
Gedurende deze opleiding werk je aan een eindopdracht waar je het geleerde toepast op jouw eigen (klant)organisatie. De meeste deelnemers kunnen daarom binnen werktijd aan de opdracht werken. In alle andere gevallen houd je rekening met maximaal 15-20 uur studiebelasting.
Interactieve Data Science opleiding & AI
De opleidingen van de Passionned Academy worden zeer gewaardeerd, onder andere vanwege de grote mate van interactiviteit en deskundigheid van de docenten. Iedere opleidingsdag is er voldoende gelegenheid om eigen cases in te brengen en ervaringen met andere deelnemers uit te wisselen. Gedurende deze Data Science opleiding werk je aan een concrete opdracht, waardoor een ideale mix ontstaat tussen theorie en praktijk.
Na afronding van onze unieke Data Science opleiding ontvang je een digitale badge voor LinkedIn, een certificaat van de Passionned Academy en een door de auteur gesigneerd exemplaar van de boeken ‘De intelligente, datagedreven organisatie’ en ‘Datacratisch werken’.
Doelgroep voor deze Data Science training
Deze Data Science training is opgezet voor iedereen die een datagedreven organisatie wil realiseren en tegelijk de intelligentie wil verhogen van zijn of haar bedrijf met behulp van algoritmes. Onze opleiding is vooral gericht op (aankomend) Data Science managers, Business Intelligence managers, Chief Information Officers, business managers, programmamanagers, Chief Data Officers, controllers, business analisten, BI-consultants, informatiemanagers, Data Scientists, adviseurs en data analisten.
Leerdoelen Data Science opleiding
We stomen je klaar om data science met succes toe te passen in allerlei situaties en functiegebieden. Onze docenten helpen je (persoonlijk) met het behalen van de volgende leerdoelen:
- Je weet hoe je de techniek van BI & AI kunt vertalen naar de business en vice versa
- Je realiseert je dat het businessperspectief van data science kritiek is voor succes
- Je hebt scherp op je netvlies staan hoe data science kan bijdragen aan innovatie
- Je hebt een veel beter begrip van KPI’s, big data en machine learning
- Je begrijpt Generatieve AI tot in detail en je ziet alle mogelijkheden
- Je kunt een sluitende business case opstellen voor AI en data science
- Je weet hoe je een AI-first strategie kunt implementeren en je ziet de risico’s scherp
- Je beheerst de basistechnieken voor datavisualisatie en storytelling
- Je weet hoe je masterdata, metadata en open data kunt toepassen en beheren
- Je beschikt over de noodzakelijke statistische kennis en kunt deze juist toepassen
- Je hebt geleerd hoe je een robuuste Data Governance-structuur opzet
- Je weet hoe je een machine learning model kunt trainen, testen en valideren
- Je hebt gewerkt met Python en kennisgemaakt met R
- Je herkent de belangrijkste valkuilen rondom privacy en data-ethiek
- De groepsopdracht geeft je genoeg bagage om data science van a tot z te regisseren
Meld je nu aan voor onze Data Science training
Via ons inschrijfformulier kun je jezelf direct inschrijven voor de eerstkomende training Data Science. Maar er zijn natuurlijk ook andere opties beschikbaar. Wil je deze Data Science training liever incompany organiseren, of heb je nog vragen, neem dan gerust contact met ons op.
De trainers: Jack Esselink, Dick Pouw en Daan van Beek
Onze Data Science opleiding wordt gegeven door Jack Esselink, Dick Pouw MBA en Daan van Beek MSc. Deze heren hebben tezamen meer dan 70 jaar ervaring in het vak en geven les op diverse universiteiten, waaronder TIAS, School for Business & Society. Tevens geven ze masterclasses in binnen- en buitenland.
Over Passionned Group
Passionned Group is de #1 in AI & Data Science opleidingen. Onze ervaren docenten laten je AI en Data Science niet alleen begrijpen maar geven je ook de juiste tools en inzichten om het te implementeren in jouw bedrijf. Om het jaar organiseren wij de Dutch BI & Data Science Award™.Veelgestelde vragen
Wie is de gebruikelijke doelgroep van deze Data Science training?De training is bedoeld voor professionals zoals data science translators, consultants, adviseurs en managers die data science en AI effectief willen kunnen toepassen in hun organisaties.
Hoe lang duurt de Data Science training en waar wordt deze gegeven?
De training beslaat 10 dagen en wordt gehouden in Berghotel Amersfoort in het midden van het land. Uit het hotel stap je zo de bossen in voor een wandeling of moutainbike tocht.
Wat zijn de kwalificaties of vereisten om aan deze cursus deel te nemen?
De training is op HBO-niveau en richt zich primair op managers en professionals met een bedrijfskundig perspectief op data science en AI. Natuurlijk kun je met een meer technische insteek de cursus ook goed volgen. Er is geen vooropleiding vereist maar wel werkervaring.
Biedt de opleiding certificeringen of punten voor professionele ontwikkeling?
Ja, deelnemers ontvangen voor deze Data Science opleiding 50 PA-punten. Informeer daarnaast naar de punten voor je Permanente Educatie (PE) bij beroepsverenigingen. PA staat voor Passionned Academy.
Is het nodig om een computer mee te nemen naar de Data Science trainingen?
Deelnemers wordt aangeraden een laptop mee te nemen naar de training. Deze is handig voor hands-on oefeningen en het volgen van het cursusmateriaal. Maar ook als je geen laptop meeneemt kun je de volledige opleiding prima volgen.
Is deze Data Science opleiding ook geschikt voor beginners?
De opleiding is bedoeld voor leidinggevenden en professionals die interesse hebben om diepgaande (praktisch toepasbare) kennis op te doen over Data Science, machine learning en AI en die hun kennis en vaardigheden willen uitbreiden. Of je nu start met Data Science of al ervaring hebt opgedaan, dat maakt niet uit. De opleiding is zowel geschikt voor beginners als verdiepers.
Krijg ik huiswerk mee of moet ik opdrachten uitvoeren tijdens de opleiding?
Opdrachten en praktische oefeningen vormen een belangrijke component van deze praktijkgerichte opleiding. Zo zorgen we dat deelnemers de theorie kunnen toepassen op hun eigen werksituatie. De eindopdracht kost waarschijnlijk het meeste tijd: maak een veranderplan voor jouw organisatie om Data Science op de kaart te zetten of om naar een hoger volwassenheidsniveau te groeien.
Zijn er netwerkmogelijkheden tijdens de training?
Onze trainingen bieden zeker mogelijkheden om te netwerken met collega's en professionals uit het vakgebied. Een flink deel van de waarde van deze Data Science training is dat je veel interactie kunt hebben en ervaring kunt uitwisselen met andere deelnemers uit andere sectoren of beroepsgroepen.
Is er ondersteuning na de training beschikbaar?
Onze trainers zijn beschikbaar voor begeleiding en advies indien nodig. Ook kun je bij ons terecht voor de inhuur van data scientists, data engineers of een interim data science manager.
Welke praktische projecten of casestudy's zijn inbegrepen in de training?
Gedurende deze opleiding kom je in aanraking met tientallen casestudies uit verschillende sectoren in het binnen- en buitenland. Denk bijvoorbeeld aan de Brandweer Amsterdam, PON, Netflix, Veiligheidsregio Noord-Holland-Noord, Coolblue en Fietsenwinkel.
Kan ik mijn deelname annuleren als ik de cursus niet kan bijwonen?
Tot 30 dagen voor aanvang is annulering kosteloos maar daarna wordt een deel van of het totale inschrijfgeld doorbelast. Bekijk hier onze voorwaarden.
Hoe wordt de cursus up-to-date gehouden met de nieuwste ontwikkelingen in data science?
Elk jaar wordt het cursusmateriaal geactualiseerd.
Wat is de balans tussen theoretisch en praktisch leren in de cursus?
Er is een goede balans tussen theorie, groepsdiscussie en praktijkopdrachten. Bij elke module krijgen de deelnemers een praktijkopdracht.
Hoe komt de cursus tegemoet aan verschillende leerstijlen?
De docenten hebben langjarige ervaring (10+ jaar) met lesgeven, het begeleiden van groepen en coaching. Ze kennen het klappen van de zweep en je mag verwachten dat er wordt ingespeeld op individuele leerstijlen.
Wat vinden deelnemers van deze training?
Jeroen van der Zande | Axians Business Solutions: Uitstekende kennis en ervaringen van de cursusleiders, ze zorgen ervoor dat je goed overzicht krijgt over alle aspecten rondom data science en AI. Een aanrader voor diegene die binnen de eigen organisatie met data science aan de slag willen en concrete handvatten nodig hebben.Telle van Schaik | Waterschap Vechtstromen: Goede complete overview. De mystiek van AI is een stuk kleiner geworden. Veel input gekregen voor het dagelijkse werk. De rugzak is goed bijgevuld.
Ministerie van Defensie: Leuke datascience overview cursus met interessante AI oefeningen en opdrachten.
Jacco Voets | Libéma Exploitatie: Goed overzicht van totale data stroom, ook AI stuk erg leuk, goed om te werken met modellen, wel bepalen welke modellen. Deskundige leraren!
Erol Kandemir | min. VWS: Raakt bijna alle aspecten van data en inhoudelijk actueel en zeer vakkundige docenten.
Jeroen van der Hagen | Gemeente Rotterdam: Ik heb de opleiding in zijn geheel als zeer waardevol ervaren. De opleiding is erg breed, waardoor je alle facetten rondom data science mee krijgt. Tijdens de sessies is er veel ruimte voor discussie, waardoor al je vragen op het gebied van data science aan bod kunnen komen. De docenten zijn stuk voor stuk vakmensen, met een enorme bak aan kennis en ervaring.
Januar Himantono | Pentair Water Process Technology: Vind het heel leuk om deze opleiding gevolgd te hebben. Enerzijds bevestiging gekregen over wat ik al heb gedaan en anderzijds ook bredere kennis over het vakgebied data science opgedaan.
Jan-Bart Smulders | PostNL: Deze opleiding geeft een serieuze verdieping in een groot aantal BI en Data onderwerpen die mij goed helpen in de aansturing van mijn team en in bewustwording creëren bij mijn stakeholders in de organisatie. Het is een juiste afwisseling van theorie, eigen cases uitwerken en oefenen. Dit helpt enorm in het me kunnen verplaatsen in de verschillende data rollen die er zijn, van beslisser tot IT architect en van Data Scientist tot Data Manager.
Iris van Meegdenburg | Provincie Zuid-Holland: Praktische voorbeelden, interactieve lessen en verschillende inzichten van leraren zorgen ervoor dat complexe stof op begrijpelijke wijze wordt gepresenteerd. Tijdens de les passen we de informatie gelijk toe op onze eigen organisaties en horen we hoe organisaties van medestudenten zijn ingericht; dit zorgt voor veel nieuwe inzichten. Zeker een aanrader!
Susanne van der Meer - Alkemade | LUMC: Een integrale benadering van het vakgebied met voldoende diepgang om de wereld van datascience beter te begrijpen.
Nicole Borkens | Gemeente Rotterdam: Na deze opleiding heb je een compleet overzicht van het vakgebied ‘data science’. Soms flink de diepte in, maar veel praktische handreikingen voor je eigen organisatie. De interactie met medecursisten is super!
Nt2 Mundium College: Het is een mooie afwisseling tussen theorie en praktijk. De gesprekken met de mede cursisten over de opdrachten zorgen voor meer inzicht in de eigen situatie. Een mooi overzicht van nagenoeg het hele domein van Data Science, met voldoende koppeling aan de praktijk. Drie domeinexperts, die elk op hun eigen wijze bevlogen over hun onderwerp presenteren.
Geert van Zon | Startselect: In deze opleiding krijg je een goed overzicht van de vakgebieden Business Intelligence, Data Science en alles wat daar mee te maken heeft. Aan het eind van de opleiding bleek deze informatie ook praktisch toepasbaar voor mijn organisatie.
John de Zwart | Varo Energy BV: Een inspirerende opleiding die het brede landschap van datascience goed en in detail beschrijft
Monuta NV: Leuke en interessante opleiding. Met name de dagen van Jack vond ik erg interessant en goed gepresenteerd.
Martijn van Dusschoten | a.s.r.: Praktisch opleiding waarin alle onderdelen op het gebied van data science worden behandeld.
Hatraco: Heeft alle aspecten belicht en mijn begin vraagstukken zijn prima beantwoord. Prima opleiding!
Kadaster: Het was een zeer geslaagde training, veel informatie in toch wel korte tijd die op een duidelijke manier door de drie docenten werden gepresenteerd en uitgelegd. Het praktische deel van data science was ook zeer interessant en gaf goed inzicht hoe AI werkt.
Niels Bissegger | Evides: De opleiding was holistisch & pragmatisch. Naast te weten welke stappen ik wél kan zetten in mijn organisatie, weet ik ook waar het nog te vroeg voor is.
Peter Vader | Gemeente Alphen aan den Rijn: Ik vind deze opleiding Master of Data Science goed aansluiten bij de omschrijving. Het geeft een doorkijk op de wereld van data gebruik. Waarom moet je data gebruiken en waar kan je het voor inzetten. Ook veel aandacht waarom data steeds waardevoller wordt voor onze maatschappij.
Frank Delva | idmsolutions: Deze data science opleiding heeft me gegeven wat me interesseerde. Ik ga verder in deze materie.
Ronald van Beers | Superunie: Mooi opleiding welke mijn kennisvraag exact heeft beantwoord. De opleiding biedt een mooie spiegel welke op de organisatie kan worden gericht.
ING: Ik zou wel checken bij mensen die me zouden vragen over de opleiding wat ze precies zoeken. Als het gaat om data science, zou ik opleiding niet zonder meer aanraden, maar rest is zeer waardevol. Als de vorm van data science anders zou zijn, zou ik opleiding zeker aanbevelen.
Wout Zwiep | Axxor BV: Zeer goed! ik ben erg blij dat ik de opleiding heb mogen doen.
Harald van Engelen | REDview BI: Heeft me precies gebracht wat ik zocht. Verbreding van het perspectief over datagedreven ondernemen, om meer de leiding te nemen in projecten. Verdieping van de technische kennis om de juiste keuzes te kunnen maken in platform, technische partners etc.
Koen van Laar | Gemeente Venlo: Goed. Het indeling van de verschillende onderwerpen was mooi. Leuke sfeer en inhoudelijk ook veel geleerd.
CCV: Ik heb veel gehad aan deze Data Science training. Ik heb nu goede handvaten gekregen om de opgedane kennis in de praktijk te brengen. Op de werkvloer konden ze al merken dat ik met deze cursus bezig was.
Jeffrey Snel | PostNL: Goede brede opleiding met goede vakkennis van de docenten. Je krijgt nogal wat puzzelstukjes te verwerken, maar als ze eenmaal vallen, dan vallen ze ook écht. Aanrader!
Gertjan van den Brink | Alfa Accountants en Adviseurs: Het is een complete opleiding die je helpt om te groeien in jouw persoonlijke DATA-ontwikkeling. De opleiding geeft je alle informatie die nodig is om de functie Data Science Translator op te pakken,
Margriet Snellen | ActiZ: Geeft een goede overview van het hele veld. Dus ook als inleiding heel goed om te volgen. Docenten maken er over het algemeen echt werk van om aan te sluiten bij waar je staat.
PinkRoccade Local Government: Breed theoretisch kader en prettige vertaalslag naar de praktijk door de docenten.
PinkRoccade Local Government: Mooie praktische handvatten. Die we gelijk hebben kunnen toepassen.
Christiaan Smith | Haaglanden Medisch Centrum: Een zeer uitgebreide opleiding Data Science. De opgedane kennis kan ik goed toepassen in mijn organisatie. Ik weet waar we staan en waar stappen gemaakt moeten worden.
Maurice Roosen | particulier: De opleiding heeft voldaan aan mijn verwachtingen. Positieve aspecten zijn de diversiteit van deelnemers en interactie binnen de groep. Daarnaast goed en behulpzaam cursusmateriaal.
Willem van der Does MBA MBB | Dutch Mountains: Zeer breed inzicht gekregen in de wereld van Data Science.
Richard Khemai | PGGM&CO: Een mooie opleiding Data Science gegeven door ervaren docenten die het op een leuke manier vertellen. Mooie praktische opdrachten.
The Future Group: Een goede, complete opleiding waarin alle aspecten van data science aan bod komen.
Univé Services BV: Goede training voor data science. Geeft een goed beeld van de diverse onderdelen die behandeld zijn en die ik zeker kan toepassen binnen mijn organisatie. Ik zou achteraf gezien deze opleiding niet in een summercourse doen, zodat je meer tijd hebt om de stof te laten bezinken.
Provincie Zuid-Holland: Goede opbouw van de opleiding en enthousiaste docenten. Kritische vragen kan ik inmiddels meer omgaan. Daar leer ik van om meer door te vragen en kritisch te zijn. Bedankt!
Frank Peek | Sanquin: Geeft een goed overall beeld van Data Science & Business Analytics. Laat de verschillende facetten goed zien en maakt het zoveel mogelijk praktisch en geeft daarmee handvatten om mee aan de slag te kunnen.
Beslist.nl: Het was een fijne opleiding, die vooral geschikt is voor personen die in een 'gesprekspartner' rol zitten in hun organisatie. Voor iemand in mijn rol was niet alles relevant, omdat ik er technisch dieper in zit en minder te maken hebt met management. Ik heb wel vernieuwde motivatie gekregen om data science bespreekbaar te maken in onze organisatie & om zelf te gaan experimenteren. 1 verbeterpuntje: soms hadden de docenten de neiging om door de powerpoints heen te scrollen en 'heen en weer' te gaan door de slides in plaats van het achter elkaar te bespreken, wat ervoor zorgde dat het voor mij soms lastig te begrijpen had & wat weinig structuur had.
Direct Lease: In de opleiding worden alle aspecten van BI en data science op heldere manier behandeld door drie zeer bevlogen trainers. Complimenten!
Veiligheidsregio Haaglanden: Door deze Data Science opleiding ben ik nu een betere gesprekspartner als het gaat om techniek. Daarnaast heb ik ook veel geleerd wat ik direct binnen mijn organisatie toe kan passen, van inrichting van goede data organisatie tot datakwaliteit verhogen.
Jurgen Zuiderduin | particulier: In 10 dagen krijg je een goed theoretisch overzicht van het vakgebied met voorbeelden en de mogelijkheid dit naar de eigen praktijk te vertalen.
Sholeh Mobaser | n.v.t.: Een hele goede basis voor het toepassen van Data Science in de organisaties.
Stephan Pals | Pals Consultancy: Super opleiding! Veel geleerd in een lekker hoog tempo. Veel vakkennis van de docenten en een hoop praktijkvoorbeelden.
Christian van der Kooi | CSK food enrichment: Een breed scala aan Data Science onderwerpen en theorieën die goed toepasbaar zijn in de praktijk.
Ben Wouterson | PDC/HRM/IDU Politie: Een traject waarin alles de revue passeert, inhoudelijk bij stil wordt gestaan met ruimte voor discussie. groepsdynamiek volop! Je leert wat Data Science echt betekent en kan betekenen voor jezelf in je werk maar ook voor het werk (de organisatie).
Result Laboratorium: Mooie brede opleiding waarin alle elementen mbt Data Science en AI aan de orde zijn gekomen. Hierdoor een beter inzicht gekregen in het vakgebied waardoor het mogelijk is een regierol te gaan vervullen.
Gert Kroeze | Automatic Choice Europe B.V.: Vertelt van begin tot eind wat data science voor een bedrijf kan betekenen en hoe daar te komen. Terminologie komt allemaal ter sprake. Up to date. Hands-on. Prima!

